

九游体育app(中国)官方网站咱们但愿更多 AI 公司约略效仿-九游体育(Nine Game Sports)官方网站 登录入口
DeepSeek 登上最新一期Nature杂志封面!九游体育app(中国)官方网站

与此同期,Nature发表 Editorial 著作称,DeepSeek R1 是首个通过巨擘学术期刊同业评审的大谈话模子,并称此举“意旨紧要”,是朝着透明度和可重叠性迈出的可喜一步。
他们写谈:“依靠安详征询东谈主员进行同业评审,是轻率 AI 行业炒作的一种样式。鉴于 AI 仍是无处不在,未陶冶证的言论对社会组成了真实的风险。因此,咱们但愿更多 AI 公司约略效仿。”

比年来,东谈主工智能,尽头是大谈话模子,正以惊东谈主的速率和一种近乎“黑箱”的样式发展。
咱们闇练的 ChatGPT、Gemini、Claude、Grok 等主流大模子,他们背后的科技公司同样吸收一套不同于学术界的效果发布样式:开直播,在预印本网站arXiv和官方时刻博客上发布突破性效果,同期在基准测试排名榜上拿下高分,终末晓谕我方具有跳跃敌手的时刻上风。
然则,这种模式穷乏传统科学领域的中枢成分:严格、安详的同业评审。
今天,DeepSeek 在Nature上发表的论文,则冲破了这一常规。

实质上,这篇对于 DeepSeek-R1 的论文早在本年 1 月就以预印本的体式发表在arXiv上。
Nature先容,不同于预印本,巨擘期刊的同业评审并非单向信息流,而是外部民众可以在由安详第三方(裁剪)监督和料理的相助经过中冷漠问题并申请更多信息。
在负责发表前,论文通过了 8 名评审的审查,并在他们的反馈下修改、完善、补充了好多报复的时刻内容。论文的了了度、真实度和齐全度都取得了进一步提高。

接下来咱们就来望望这篇论文主要讲了什么。
同样来说,擢升大谈话模子推理本事有两种主要阶梯:一是在预履行阶段通过大边界盘算推算资源达成,二是通过想维链(CoT,Chain-of-Thought)等指示时刻,讹诈假想好的样本示例或“让咱们一步步想考”这么的指示词来率领模子产生中间推理法子。
但这类步履过度依赖东谈主工标注的推理示例,本钱腾贵、膨胀性差,还引入了东谈主类领略偏见。
更报复的是,东谈主类示例是否可能扬弃模子的探索计谋,使其难以发现更优的、非东谈主类的推理旅途?
在这篇题为“DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning”的论文中,DeepSeek 团队冷漠并考证了一种饱读舞模子产生复杂推理本事的蜕变步履。
该步履以隧谈的强化学习(RL,Reinforcement Learning)为中枢,显耀划分于传统履行范式,解脱了对东谈主工标注推理轨迹的依赖。
他们的中枢想路是,完全跳过监督微调,只用强化学习优化最终收尾的正确性,让模子在无任何东谈主工示范的环境中自觉演化推理计谋。
DeepSeek 团队选择了 DeepSeek-V3-Base 看成基础模子,并吸收群体相对计谋优化(GRPO,Group Relative Policy Optimization)看成强化学习框架。履行过程中,仅对模子最终谜底的正确性进行奖励,不合推理过程进行显式拘谨。
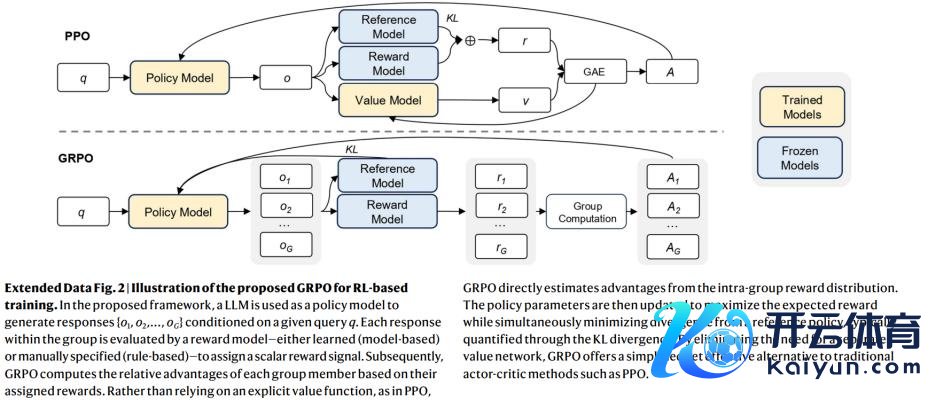
群体相对计谋优化算法可以镌汰盘算推算支拨。其中枢想想是:对于每个输入问题,先使用旧计谋采样一组反应,然后对这组反应评估奖励(同样是回答正确与否)。基于这组奖励盘算推算上风函数,并对计谋参数进行梯度更新。
换言之,GRPO 为每个问题变成一个奖励群组,通过擢升高评分谜底的出现概率来优化模子。比拟庸碌计谋梯度算法,群体相对计谋优化不需要单独履行一个同等边界的评估器,而是告成讹诈收尾集的平均或中位数等统计量看成基线。
他们不雅察到,通过这种纯强化学习步履,模子当然发展出了万般化且复杂的推理行径。
在治理推理问题时,由此出身的 DeepSeek-R1-Zero 倾向于生成更长的回答,在每个回答中融入考证、反想和探索替代决议的过程。尽管征询东谈主员并未明确告诉模子何为推理,也莫得任何监督微调(SFT,Supervised Fine-Tuning)看成入手法子,但模子仍然收效学会了推理计谋。
履行过程中,DeepSeek 团队还发现了一个真谛真谛焕发:模子出现了“顿悟时刻”。

在某个时刻,DeepSeek-R1-Zero 一会儿加多了反想过程中“等一下”的使用频率,似乎出现了自我进化。
同期,它入手自觉地在濒临发愤时期派更多的推理期间,生成更长的想维链,并重新评估和修正其发轫的解题想路。
不外,固然 DeepSeek-R1-Zero 展现出了广大的推理本事,但它也存在可读性差、谈话混用等问题,且在写稿和怒放域问答等任务上施展较差。
为了治理这些挑战,他们确立了 DeepSeek-R1,吸收了整合拒却采样、强化学习和监督微调的多阶段学习框架,使模子既保留了推理本事,又能在非推理任务上施展出色。
固然前文提到不必监督微调也可以学会推理,但实行标明,加入一丝冷启动数据可进一步擢升迭代推理模子的效果。
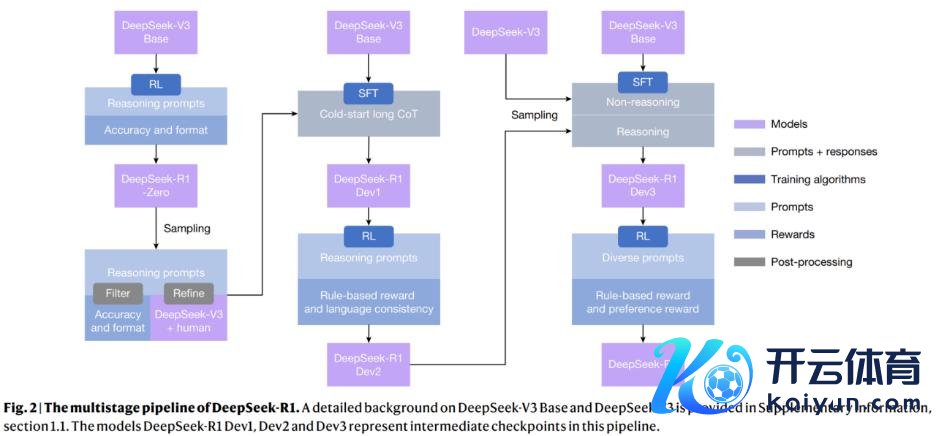
因此,在多阶段履行的入手阶段,DeepSeek 团队网罗了数千个冷启动数据,展示了对话式、东谈主类对皆的想维过程。随后应用强化学习履行,通过对话想维过程寝兵话一致性来改善模子性能。
接下来他们使用了拒却采样和监督微调,将推理和非推理数据集纳入监督微调过程,使模子掌抓了可以的写稿本事。
为了进一步使模子与东谈主类偏好保持一致,他们还吸收了第二阶段强化学习,提高模子的可用性和无害性,同期连续完善其推理本事。
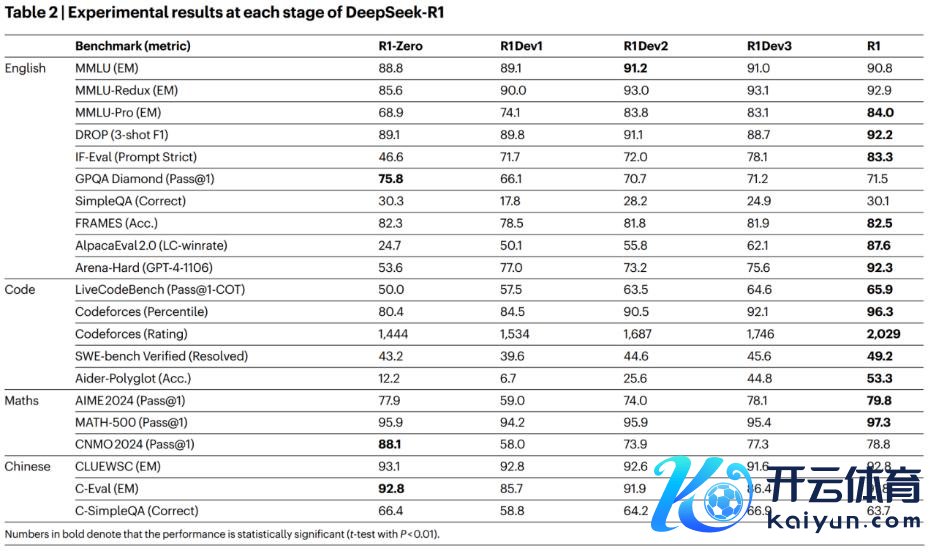
最终,DeepSeek-R1 在多个主流基准测试上施展出色,包括 MMLU、GPQA Diamond、SimpleQA、SWE-bench Verified、AIME 2024 等,其性能取得了考证。
一个典型的例子是,跟着强化学习履行的不停进行,在 AIME 2024 数学竞赛基准上的施展,DeepSeek-R1-Zero 的 Pass@1 得分从 15.6% 擢升至 71.0%,最终的 DeepSeek-R1 模子则达成了与 OpenAI-o1-1217 非常的性能。
终末,咱们看到发表在Nature上的论文比预印本包含更多的时刻细节和内容,这离不开同业评审的孝顺。
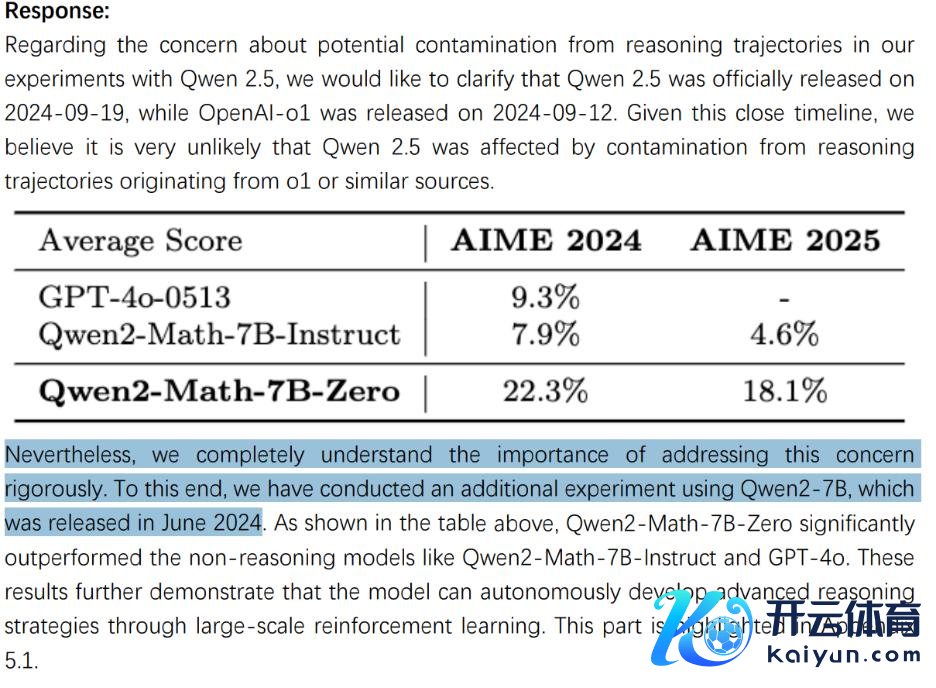
举例评审指出,群体相对计谋优化对于 DeepSeek 的蜕变步履十分报复,应该更详备地面貌该算法;使用未受推理轨迹数据欺侮的基础模子进行实验,可以让实验收尾更令东谈主降服;论文中对于模子安全的面貌过于浩繁、总共,应当进行更多的安全评估且用词愈加严谨。
针对这些问题,DeepSeek 作念出了详备复兴,包括新增多个附录内容、讹诈未受推理影响的 Qwen2-7B 进行实验等等。
可以说,DeepSeek-R1 论文发表在Nature上,除了笃定其学术价值外,还草创了一个意旨紧要的前例。
这意味着,AI 基础模子征询正从一个以时刻博客和基准测试分数为主要评价圭表的领域,迈向以步履论的科学性、可复现性和严谨考证为中枢的进修学科。
参考辛劳:
https://www.nature.com/articles/s41586-025-09422-z
https://static-content.springer.com/esm/art:10.1038/s41586-025-09422-z/MediaObjects/41586_2025_9422_MOESM2_ESM.pdf
https://www.nature.com/articles/d41586-025-02979-9
https://www.nature.com/articles/d41586-025-02703-7
排版:刘雅坤